
There’s a very interesting, partly because simply-written, article by Thompson and Smith on the dangers of making predictions from computer models here.
I wrote about the shortcomings of models back in 2014, based on a series of excellent blogs by Mike Flynn. The present article covers something of the same ground as his blog series, but especially shares the bottom-line that it has become all too easy, with the advent of highly complex computer modelling in all kinds of scientific endeavours, to believe that models generate data, rather than being more or less useful fictions that generate more or less useful numbers.
In case one thinks no real scientist would make such an elementary category error, only yesterday I saw an article with this title: “New elevation data triple estimates of global vulnerability to sea-level rise and coastal flooding.” The paper is actually about a new, allegedly improved, way of modelling land elevation, and therefore of generating alarming model predictions, not data.
The Thompson and Smith article, however, shows the fallacy of this by employing the simple analogy of “model land”:
Model-land is a hypothetical world in which our simulations are perfect, an attractive fairy-tale state of mind in which optimising a simulation invariably reflects desirable pathways in the real world. Decision-support in model-land implies taking the output of modelsimulations at face value (perhaps using some form of statistical post-processing to account for blatant inconsistencies), and then interpreting frequencies in model-land to represent probabilities in the real-world. Elegant though these systems may be, something is lost in the move back to reality; very low probability events and model-inconceivable “Big Surprises” are much too frequent in applied meteorology, geology, and economics.
They go into more detail of course (though deliberately not too much, as this was originally delivered at a meeting of non-statisticians). In particular they draw attention to two effects. The well known “butterfly effect” is that in which the inevitable inaccuracies of input data to models of chaotic systems may render the outputs wildly different from reality. However, they also point out an anagous effect termed (for reasons I am unclear about) the “hawkmoth effect,” in which the inevitable inbuilt errors of the models themselves may magnify astronomically in repeated iterations of the model.
Another recent paper, here, has generated much discussion on this effect in relation to climate prediction models, by suggesting that the error-margins generated in even their short-range predictions completely swamp any plausible range of actual outcomes (as an example, a model that predicts a 37% probability of an outcome with an error margin of 0-100% from error propagation is providing no useful information at all).
Now, the striking thing about the Thompson and Smith paper, to me, is that it implies, I believe correctly, that the misunderstanding of the limitations of modelling is not simply common, but envelops whole disciplines. Their original target-audience consisted of economists, and the best illustration of how their approach matters in that field is found in one of the open review comments at the foot of the linked article.
Responding to a critique that “the authors seem to be unaware of positions that see macroeconomic models as more general and more stable than disaggregated models,” Leonard Smith replies:
During the meeting we noted that several of the speakers, referred to as macroeconomists, said that while they thought the phenomena of the crash (the topic of the meeting) was very interesting, it was not what they did. They then proceeded to give interesting mathematical talks about macroeconomics.
Our talk was about foreseeing events like the crash and dealing with them in real time; actual economics. To be honest there seems to be some disagreement as to where or not the dynamics of the real economy is or is not a target of macroeconomics…
…As we were asked to speak on the actual financial crisis, and feel actions during the crisis (and comments made afterward) make it clear that while they are long known, the implications of structural stability are not well known. As it happens, the same applies to real world simulation in biology, medicine, psychology and sociology.
I would suggest that had decision makers had a true picture of the known limitations of their models, specifically of their limitations and the “purple light” (Smith, 2016 and new text) regions before the beginning of the crisis, they would have acted differently.
In other words, the biggest crash in recent history was unforeseen by economists because they became used to “living in model land” without really appreciating that it is not the real world. But of course, it was in the real world that economic suffering occurred. In model land everything continued peacefully according to theory.
The authors, as the quotation above indicates, recognise similar blindspots in other fields, and in particular they mention that of climate modelling, in which trillions of dollars are being invested on the basis of predictions made by models which, for one reason or another, are taken as higher truths that the actual data recorded.
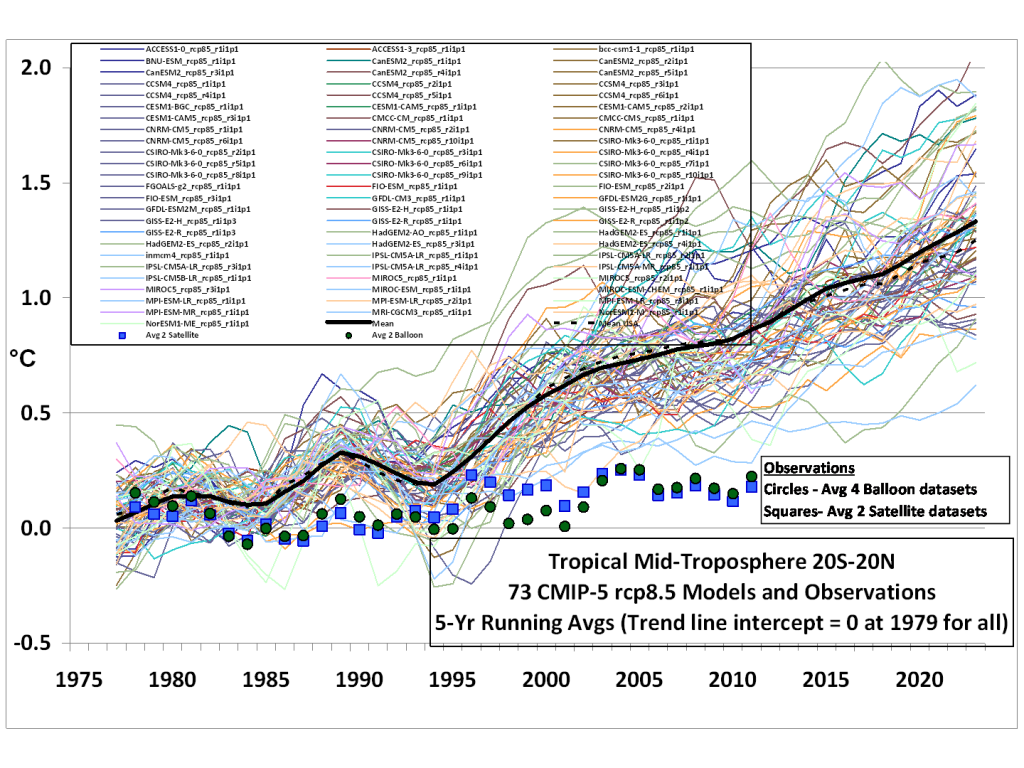
Speaking personally, it has been the increasing realisation of that apparently poor understanding of the limitations of modelling across the whole climate change field (and worse, amongst biologists and other scientists discussing climate change at places like BioLogos and Peaceful Science) that has been the main impetus for my increasing scepticism about climate change. Dirty tricks used to silence dissent haven’t helped either: I would not buy a used car from many of the climate people.
But when I read Mike Flynn’s stuff back in 2014, the most obvious application to me was nothing to do with climate (in which I had relatively little interest), but that of population genetics, a highly stylised mathematical model that has become elaborated in increasingly complex ways with the advent of computers. That very complexity beguiles us into believing it represents the real world.
That the models are useful in short-term applications like cancer research is evident from the fruit they bear. But when applied more generally and diachronically to the mechanisms of macroevolution, the assumptions made in the models are almost inevitably going to miss what our authors call “Big Surprises” (in this case including both unknown evolutionary mechanisms and chaotic aberrations, not to mention direct divine acts of which the models can know nothing). This corresponds to the difference, in the Thomson and Smith article, between “weather-like” and “climate-like” situations.
At these large scales, population genetics cannot be validated against real world events in the future, because the time-scales are too long. Nor can they be validated by the past, for not only do we lack sufficient information about ancient changes in genetics and environments, but the actual patterns of macroevolution quite clearly reveal surprising outcomes. There is not a single example in which subsequent developments could have be predicted from the fossil record or surviving species, by population genetics.
Could the theories underlying population genetics explain the world we see? Of course, because the models are tuned that way. But they could equally explain any other world, given their inbuilt uncertainties. And that which could explain everything actually explains nothing.
Uncertainty, in fact, is what seems to be so lacking in much of the science that generates most controversy in the world today. I wish one could say that the overconfidence in the predictions of models was restricted to ignorant journalists, simple-minded politicians, and apocalyptic activists. But Thompson and Smith’s paper seems to make a good case, from people who understand the proper use of models, that groupthink on the matter has weakened the cautious objectivity of entire disciplines.
The really sad thing is that, on past showing, those “guilds” will find it easy to dismiss this paper on the basis that a statistician and a mathematician know nothing about climatology, evolution, or whatever. Expert consensus, after all, cannot be wrong.
The fact that evolution can explain anything one throws at it does bother me. But couldn’t the same charge be levelled at “God”? (Like that joke about “I know the answer is Jesus, but it sure sounds like a squirrel”).
Hi Ben.
You’re right, of course – explanation of life by various incarnations of “naturalistic” evolution and by God have always been regarded as two alternative explanations. I think the answer to your question is (at first pass) twofold.
In the FIRST PLACE, one needs to recognise, as is seldom done, that the alternatives are about two metaphysical viewpoints, not about empirical evidence.
If one believes that there is a thing called “chance” and things called “natural laws” (under which chance is ultimately subsumed), and that the combination of these tends towards an organized system, then the evolutionary approach is one’s preference. If, though, one believes that the mind of God is behind the universe, then that becomes the fundamental explanation, whatever the role of secondary mechanisms might be.
Note that it is irrelevant to the question why one arrives at one’s chosen metaphysics: belief in “God” might arise from a logical philosophical process or a personal encounter with the Gospel; and belief in “nature” might be a conviction that other things seem to be the result of chance and necessity, or else simple hatred of, say, a Fundamentalist upbringing.
In the SECOND PLACE, though, the implications and expectations of the two viewpoints are different.
If one believes that natural laws are inevitably going to produce our living world, then it follows that adequate empirical investigation will be able to reverse-engineer the past or predict the future. Science is about demonstration, and where the validity of theory cannot be demonstrated, science actually stops and religious faith in “naturalism” takes over.
If, however, God is a voluntary agent, then contingent events are the result of choice, not necessarily law, and the lack of predictability is a logical outcome from God’s freedom. Consequently, failure of prediction tends either to point away from naturalism, or to reduce its epistemological force from “evidence” to “faith.”
I should add that all this is an aside from the question of models in the OP. Seen sociologically, though, overconfidence in models may be a symptom of the desire to make the extent of scientific knowledge greater than it is, rather than to admit its limitations and, therefore, the role of unsubstantiated faith in a metaphysical position.