
YouTube, somehow tapping into my brainwaves, suggested this video to me, about the effort to interpret the alphabetic inscriptions of the Indus Valley civilization.
It’s intrinsically interesting in its own right, in the use of computer tools to begin to unpack one of antiquity’s greatest linguistic riddles, a written language for which there is no Rosetta Stone. But it’s also instructive (from my point of view) because it mentions both the separateness of this civilization from the contemporary Mesopotamian civilization in which the Old Testament has its deepest roots, and its cultural connections to it. For the significance of that to Genealogical Adam see here, or this recent comment on Peaceful Science.
The video points out examples of Indus Valley artifacts found in Mesopotamia, dating from 2600BC or before, where analysis shows unusual symbol combinations suggesting transliteration into another language, perhaps by a visiting trader. This confirms graphically (literally!) the longstanding trade-links to the East that the Bible writers must have known about, but omitted from the Table of Nations. For those interested, there is a more detailed scholarly examination of the extent of those cultural exchanges on another YouTube video here.
However, the burden of this post is something else entirely, in the form of the graphic below, which was shown (as the screenshot shows) ten minutes into the talk. It shows, obviously in stylized form, the information entropy of linguistic scripts compared to other things. The purpose in the presentation is simply to show that the Indus Valley inscriptions do, contrary to some opinions, have linguistic meaning.
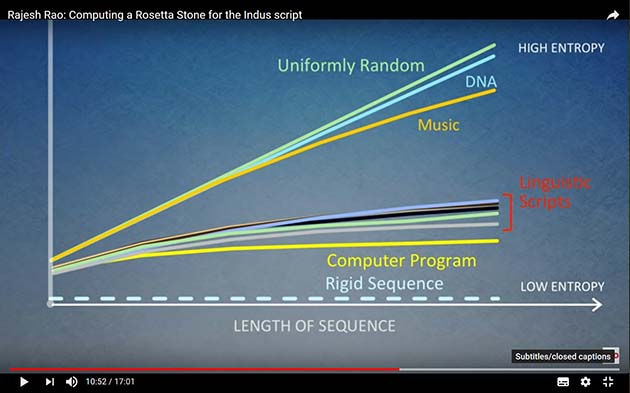
The diagram, though, seems also to bear on the long and highly technical discussions Joshua Swamidass and others have had on Peaceful Science (and before that, on BioLogos) with various Intelligent Design proponents, in relation to the information content, or lack of it, in DNA. In that context, what obviously drew my attention was the closeness on this slide of the line for (genomic) DNA to that for “uniform randomness.”
Compare that with the intuitively obvious lower entropy of computer algorithms as compared to the more flexible nature of written language… but also with the trace for instrumental music, which is a lot closer to randomness than are the written scripts. There is clearly, from that last fact, more to be said, because as a composer and arranger of instrumental music I know that music is not random at all, but highly – even obsessively – designed. Words, in prose at least, are usually sufficient if they adequately express meaning – music has to be right.
The nature and context of the illustration clearly leave a lot about its derivation unexplained. How large a chunk of genome was sampled, for instance? But whilst I can imagine some Epicurean gloating that the DNA line shows that random neutral changes can easily produce the human genome, that cannot be what it shows. The question had me downloading a few articles on “DNA compression” to see what light they could cast.
My articles showed (not surprisingly) how complex the question is. There is a practical interest in compressing DNA data, purely for economy of storage in databases, and some papers offered methods of doing that. On the other hand, mathematical papers emphasised the difficulties of compressing genomic data, therefore reflecting its high entropy.
One paper rightly reminded us that “randomness” is always contextual, not absolute – a point I’ve often made myself. For example, one way of compressing data on multiple human genomes is to compare their differences from a reference standard, individuals differing by only 0.1%. On this measure, the human genome is very highly organised and so compressible, by virtue of the efficiency of the human reproductive mechanisms in maintaining humans as humans. This, however, is a different context for assessment than comparing a genome with a random string of bases.
But the randomness of the genome is also limited by the high percentage of repetitive elements, which some measures ignore, so perhaps that was done to the data in the graphic – we’re not told. Coding DNA has higher entropy than repetitive elements – and yet this is the portion of the genome most clearly linked to organised function, and most subject to the non-random process of natural selection. So exactly what measure the graph in the illustration is taking we don’t know, but it is clearly masking some complexities.
As, indeed, in the line on the graph for “instrumental music.” What high-entropy source of music, I wonder, is being measured here? I suspect that the work was done on audio files, rather than on, say, scores in standard notation. For whilst the latter contain information for time and pitch, and even dynamics, lacked by written-language documents, they are likewise composed of a limited number of symbols in constrained relationships, and I would expect scores to contain, broadly speaking, comparable information entropy to written documents.
What makes a sound file bigger and less compressible is that, as well as the information in the score, it contains all the variations in musical expression – time, volume, attack, vibrato and much more – together with much information from the acoustic environment itself, such as reverberation and echo. An actual orchestral performance, produced by dozens of intelligent interpreters of the score under a skilled conductor, contains much more “designed” information than the written score, and yet this paradoxically brings it closer to the “uniformly random” character of meaningless noise.
But this reminds us that the relative “rigidity” of the linguistic scripts on the graph hides a similar phenomenon. Written language, like notation, is actually merely a shorthand for human speech. Expression, timbre, timing and so on – quite apart from meaning – are omitted from the inscription, and left to the interpretation of the intelligent reader. Ancient languages lacked even punctuation, vowels and word gaps.
So if the speaker in the video were not interested primarily in Indus Valley script, but in spoken language, a comparison of the information in a recording of speech would, in all probability, be higher in information entropy even than instrumental music, even though containing all the additional interpretation than turns mere letters on a page into a stirring or pathetic speech-act.
It seems paradoxical that some orator’s address to a crowd might overturn an empire far more than a written transcript of his speech, and yet be closer to randomness.
And this brings me back to the DNA question. After the discovery of the genetic code, DNA was viewed as a linear algorithm, computing the sequence of proteins. Yet on the graph it looks even less like an algorithm than it does like a linguistic script.
But this view, of course, neglects later discoveries, such as the three dimensional structure linked to epigenetic expression, the regulatory effects of repetitive elements, and the sheer inter-connectedness of elements across the genome. What looked much like printing on a page (or, if you are Richard Dawkins, LIKEAWEASEL) has in the organism complexities that, like the dynamics and expressions in a piece of music, increase the information entropy and, hence, the appearance of randomness.
And of course we do not actually know the half about what is happening with the genome in life. Every scientific abstraction of information from the genome is, in one way or another, the reduction of an actual performance of life to some kind of tractable notation. The more complex life is – even the more designed – the less, it would appear, will it differ in information entropy from the completely unplanned and random, if such exist.
And compared to an inscription from Mohenjo-Daro or a Mahler symphony, a living organism is very complex indeed.
I have watched some good youtube vids on the Indus valley too.
I don’t agree its 2600 years ago. instead about 200BC to 1600BC.
the bible breakdown of peoples after the flood would include somewhere these people.
I think its Ramah. This because it would of been a real man, a long lived leader, and then turned into a God. the famous Ramah God of india. Also the name comes up in trading between Sidon/Tyre etc later on. indeed they find s india wares evidence in philistine etc areas.
Someday someone will figure out the script i think.
“I don’t agree its 2600 years ago. instead about 200BC to 1600BC.”
I won’t ask your evidence for that, because I think you do intuitive guesses rather than evidence (actually it would be 4,600 years ago – 2600 BC). But you do, I suppose, realise that you’ll have to make the ancient Babylonian culture 200-1600BC to match, which means that Abraham would have moved to Canaan around the time that Moses was coming oiut of Egypt, or after?
I understand Abraham was about 1900bc by the dates in the bibles I know.
Its only these calculations I go by. They extrapolate backwards. Thats how 4004 BC was figured out for creation week.
I do think the Babylonian first civilization is easily squeezed into the first centuries after babel. The bible does insist babel/Babylon was the first post flood city. Then a empire was created quickly.
I like the Ramah idea of men turned into Gods by the people. Likewise our own first father. GOMER(German) and from his son TOGARMAH (Thor0 and tomorrow is Thursday.
He also lived hundreds of years, died, made into a God9they knew he existed) and thus remembered ever since in the eastern Germans.
Likewise Mizraim(Egyptian) became RA.
Its educated speculation.