
There’s an interesting new paper here. It’s by four Irish authors (which has to be a good thing), two of whom declare their “conflicting interests” as signatories of the Great Barrington Declaration and (in one case) as a member of HART. However, in their declaration they note that the purpose of their involvement in the study was to understand the position of their opponents better.
The key thing is how they identify the two major schools of dissent over the COVID phenomenon in terms of two conflicting Kuhnian paradigms, whose conclusions are more or less bound to follow from their starting assumptions. The problems have been (a) that the paradigms lead to opposite interpretations of the facts and to radically different policies and (b) that one paradigm has been allowed to dominate policy-making to the detriment of science. The authors advocate a wider involvement of scientists from both positions in advising governments – they are not the first to do so, of course. The blue team – red team approach works for industry, and is much needed in many sciences, and especially medicine.
Whether their claim that the opposing positions are actually true “paradigms” in Kuhn’s sense is strictly correct is questionable, but it is still a useful lens to see how two entirely different methodologies account for much of the scientific disagreement (if not for the role of socio-political and commercial interests in enforcing the prevailing view).
You can read the paper as well as I, but the basic difference in the two approaches is this:
Position #1 takes for granted epidemiological theory that was developed in the 1920s, and applies it rigorously using complex computer modelling. The effectiveness of measures like lockdowns is therefore assumed on theoretical grounds, and the failure of the models’ predictions is taken as evidence of the success of the measures so imposed.
Position #2 takes a more empirical and evidence-based approach, judging the need for, and effectiveness, of policies – and by implication the truth of epidemiological theories – on the real-world data, closely scrutinised.
The difference explains why SAGE or the CDC point to millions of lives saved by lockdowns, masks or vaccines, whereas opponents see no evidence of such numbers, and instead point to controls like Sweden or Florida where lack of masks and lockdowns have not led to huge numbers of deaths, or to countries with low vaccine rollouts where deaths might be similar to, or even lower than, highly vaccinated nations like the UK or Israel.
Though it is not highlighted in the paper, I find it interesting to consider why modelling in 2020-21 has led to such disruption to society, whereas previous pandemics since the 1920s, presumably understood using the same theoretical framework, have not.
Arguably such modelling has previously caused disruption, if one includes the disaster of the last UK Foot and Mouth epidemic, or the management of “mad-cow disease,” to our agricultural industry. Both were based on the same theoretical epidemiology computer models. But as for human pandemics since that time and before COVID, they have all been small enough to peter out before much major damage was done, though the models made equally outlandish predictions.
But the larger pandemics before that, such as the Hong Kong Flu of 1968-9, or the Asian Flu of 1958, were numerically similar to COVID, yet went relatively unnoticed. The difference is that back then, there was no significant computing power to construct the models that would apply the theories rigorously to the real world. Neither were there large-scale tests like PCR available to monitor the progress of the epidemic (which of course have produced their own batch of problems).
Crudely speaking, the world dealt with, say, Hong Kong Flu by realising there were large numbers of flu-like illnesses leading to death, spreading round the world; and by counting the excess deaths later they could judge its total or regional impact. Even antibody tests were not widely available to assess communal immunity. And that was not a major problem, since the theory was correct enough to enable broad contingency measures to be put in place to limit the damage.
If there were major flaws in the epidemiological theory, they would remain hidden for lack of reliable data. But with COVID-19, computer modelling has enabled the application of the old theory to the whole world, and its assumptions to form and modulate public policy day by day. Any errors in the theory will therefore be amplified by the models.
And errors there are bound to be, because the theories of the 1920s made simplifying assumptions that are just not true in the real world, which the article points out. For a few examples, the theory assumes a total absence of immunity for a new pathogen, which was found to be false very early on in this pandemic, partly because of cross immunity with common coronaviruses and SARS-1. Then it assumes that the spread of the epidemic will be homogeneous, whereas we have seen repeated local, often unpredictable, outbreaks which are self-limiting (the famous Gompertz curves have become familiar to everyone). Also, immunology was in its infancy in the 1920s, so that the role of non-antibody immunity via T-cells, B-cells and other modalities really did not come into the maths.
Yet we see, under Paradigm #1, these simplifications largely being ignored: the models took it for granted that, all other things being equal, spread would be exponential unless and until vaccination could produce herd immunity. The spontaneous turn-around and fall in cases in every single outbreak around the world was attributed to whatever intervention approximately coincided with it: lockdowns, mask-mandates, vaccination programmes etc. An exception like Sweden was either said to have practised such measures unobserved, or was simply ignored as an anomaly – or even classed as a disaster that proved the models in despite of the actual data.
Likewise, antibody levels have been taken as the be-all-and-end-all of immunity, inherent immunity and T-cell immunity being largely ignored. Consequently, as antibody titres after vaccination are seen to wane over a few months, or as a new variant appears, everything in the models has, in effect, to be reset to zero: the situation becomes like a new pandemic, and exponential numbers of cases and deaths are just round the corner again – as is seen in the continued dire predictions for the winter now coming out of SAGE.
For the rest of this piece, I won’t go further into the COVID question, and will leave you to consider how much of the problem is, as the article says, the result of a dominant methodology based on inadequate science, but dignified by the complex technology used to bolster it. Instead, I’ll point to the fact that this trust in hugely complex computer models, based on over-simplified mathematical theories, has become the uncritical backbone of much of the science that affects us daily. It is that Faith in the Model, rather than simply a particular theory of epidemiology, that is the Kuhnian paradigm in need of shifting.
The most comparable example is, as you will probably already appreciate, climate science. The whole panic over climate change arises from the predictions of models even more complicated than Ferguson’s string-and-ceiling-wax COVID model. The dynamics of the world’s climate are far more complex than those of viruses (or at least, that’s what we assume, which is not a safe bet since we can’t predict either). Yet for all their complexities and their infinite capacity for being wise after the event, climate models are based on a simplistic theory of climate, in which one factor – carbon dioxide levels – is assumed to be almost the only significant controller of the world’s average temperature.
I’ve just read Steven Koonin’s excellent book, Unsettled, which makes the case for the reality of this oversimplification scientifically but accessibly. But one only has to look at a figure like this to see the problem playing out:
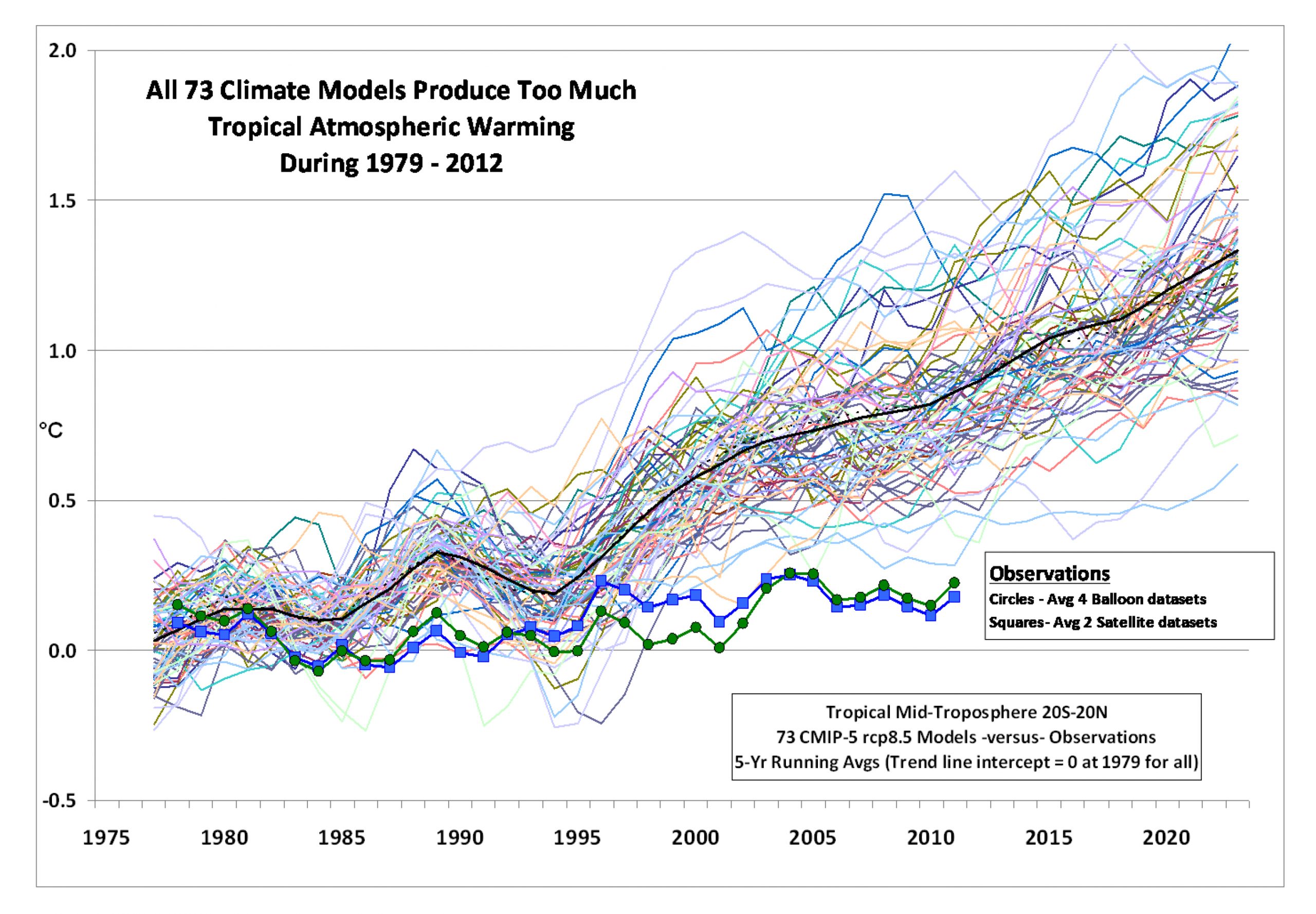
Crucial to the whole anthropogenic warming theory is that the first indicator of climate change is the mid-tropospheric temperature in the tropics. But compared to direct satellite and balloon measurements, all the models are running increasingly too hot, by a large degree. Koonin points to papers that fail to account for this, but which conclude that the data must be in some way misleading because the models are to be preferred.
This is characteristic of how scientific paradigms deal with inconvenient data, until they are overturned. But even if that explanation were correct, it does not explain why such a hugely disparate set of models, predicting almost every temperature above that actually observed, should continue to be accepted despite their mutual contradictions. Still less is it clear why bodies like the IPCC should take an average of these, when the vast majority of them must be wrong. If economists were equally divided between a coming boom and an imminent bust, no sane government would assume the future is “steady as she goes” on average.
I mention as my final example that of population genetics, because it was what demonstrated to me, years ago, the existence and problematic nature of the “computer modelling ” paradigm. Population genetics is another theory incorporating many, known, oversimplifications, and which largely ignores many of the highly complex discoveries about evolution that have emerged since the theory was formulated back in the 1930s.
As applied to the Big Picture of life’s origins, it only really affects us at the metaphysical level of making evolution look plausibly scientific and, basically, simple. Its more useful application, of course, is to understand and predict the microevolution of things like viruses. In this it is indeed passably useful in explaining, and to some extent predicting, the pattern of genetic changes produced by natural selection, drift and so on.
Even so it is worth remembering that the more complex these models are (and they have to be very complex now both for real-world problems and academic phylogeny), the more they have to be tuned by the programmer, or perhaps increasingly by AI, to compensate for their weakness in predicting reality. So when they work, it is not because the underlying theory is necessarily correct, but because parameters have been adjusted to make the model good enough to work in its restricted application. And that’s fine, given the famous adage that “all models are wrong, but some are useful.” But note that the assumption is that the underlying theory itself is true, even if one has to adjust parameters one can’t actually measure in the real world.
I noticed early on how, in unravelling the macro-evolutionary history of the past from the genetic markers of the present, it is actually impossible to calibrate the model against reality, because the reality is in the past, and the past is dead and gone. So it ought to be no surprise to discover the often bitter disputes between palaeontologists and morphologists, determining historical changes from the patterns of the fossil record and the anatomy, and the modellers establishing phylogenetic relationships based on modern organisms and population genetic theory programmed into super-computers. Disagreement between the two approaches is the norm, not the exception.
How this matters scientifically is that one of these approaches becomes the ruling paradigm, and it seems to me that the fascination with technology has put the modellers in the driving seat. I remember reading the comments on a BioLogos thread about this dispute, and the prevailing view seemed to be that computers are wonderful, and population genetics mathematical and precise, and therefore superior to old disciplines like palaeontology, which rely on spades (of all technologies!) and the merely human vagaries of connoisseurship.
But this technological edge is basically illusory. Yes, the palaeontologist may look at his fossil data and make a human judgement. But the modeller’s computed solutions are no stronger than the theory that was originally fed into the model, and that theory came from some scientist looking at his data and making a human judgement.
In the case of population genetics, for all the modifications to the models, that human judgement was made by scientists in the 1930s. In the case of COVID-19, the human judgement was made in the 1920s. The age of a theory is a mark neither for nor against it, but we always need to remember that a spectacular superstructure is only as sound as its first foundation. In science, better data regularly require digging entirely new foundations.